L1: Foundations of Deep LearningThe perceptronLossTraining neural netsExampleNeural networks in practiceFinding
L1: Foundations of Deep Learning
If we repeat a number of simple mathematical operations millions, billions, even trillions of times, these simple additions, multiplications, and so on begin to develop a complexity seemingly greater than the sum of their parts. Machines that perform enough calculations in just the right structure seem to develop their own personalities, forming "ghosts in the machine."
Machine learning has been around for a long time. Many of the underlying concepts, such as backpropagation and stochastic gradient descent, were established decades ago, but only recently has our technology allowed us to achieve the sheer scale required for the ghosts to emerge.
Let's begin by settling some broad terms. First, AI is a technique that enables computers to mimic human behavior. Within AI, machine learning (ML) is the ability for computers to learn without explicit programming. And within ML, deep learning is the extraction of patterns from data using neural networks.
The perceptron
Neural networks are made of individual units that are sometimes called "nodes," sometimes "neurons," and formally called perceptrons. Each perceptron solves math problems that might appear on a first grader's homework assignment.
A simple perceptron has one input

Our world is not linear. It's a lot more complicated than that. And so we need to add another piece to our perceptron, a non-linear function

Our perceptron's calculation then becomes:
In other words, our perceptron first multiplies each input by its respective weight, sums all of these products together, and sends the result through our non-linear function.
What non-linearity should we choose for
 `
`
For simplicity, we can restructure (
where
We stack and chain individual perceptrons together, forming a network where inputs are passed from the beginning, through several stacks of perceptrons, to a layer of outputs
Loss
Before we talk about how these networks are trained, let's consider how their performance can be measured in the first place. Loss quantifies the cost of a network's mistakes. For a given input (say a picture or audio clip)
where
Cross entropy loss is used for models that output probabilities (values between 0 and 1):
Finally, mean squared error (MSE) is used for regression models with continuous real numbers:
Training neural nets
How can we minimize our loss? We simply need to find the optimal set of weights
To determine the global minimum of a differentiable function, we can employ gradient descent. For each weight
To calculate each partial derivative, we use the chain rule, working our way from the output back to the desired weight. This gives us the value by which we could adjust
Since this process requires us to calculate the partial derivates from the end of the network back to the beginning, we call it backpropagation.
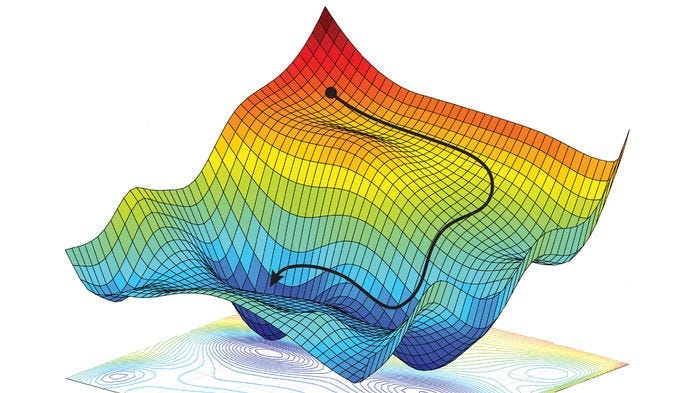
Gradient descent across two variables. [Source]
Example

Consider the simplified network above. The partial derivatives via the chain rule are:
Neural networks in practice
Finding
Finding
Often, engineers find
- Stochastic gradient descent
- Adam
- Adadelta
- Adagrad
- RMSProp
Batching
Gradient descent is a very expensive calculation to perform. To speed it up, we can run GD on just a selection of our training data. Since this selection should approximately represent the whole dataset, we should achieve similar results while achieving much higher performance.
Overfitting
Overfitting prevents our models from generalizing to new information. We can employ regularization techniques to prevent overfitting. These constrain the optimization problem during training to discourage complex models.
The most popular regularization method is called dropout. In this approach, we randomly select some nodes in our network and set their activations to zero. This random selection, typically about 50% of a network's perceptrons, changes during each training cycle, and prevents the network from relying too heavily on any single node.
Early stopping, a very broad category of regularization, identifies the point of divergence between training and test set accuracies during training. When the two accuracies diverge, this is a clear sign that overfitting has begun.